Het voorkomen van Context Rot door context engineering
Context Rot is als de LLM minder precies wordt naarmate meer van het context window van het taalmodel gebruikt wordt. Gelukkig kun je hierop mitigeren door je context zorgvuldig te ontwerpen met behulp van context engineering principes.


De definitie van Context Rot
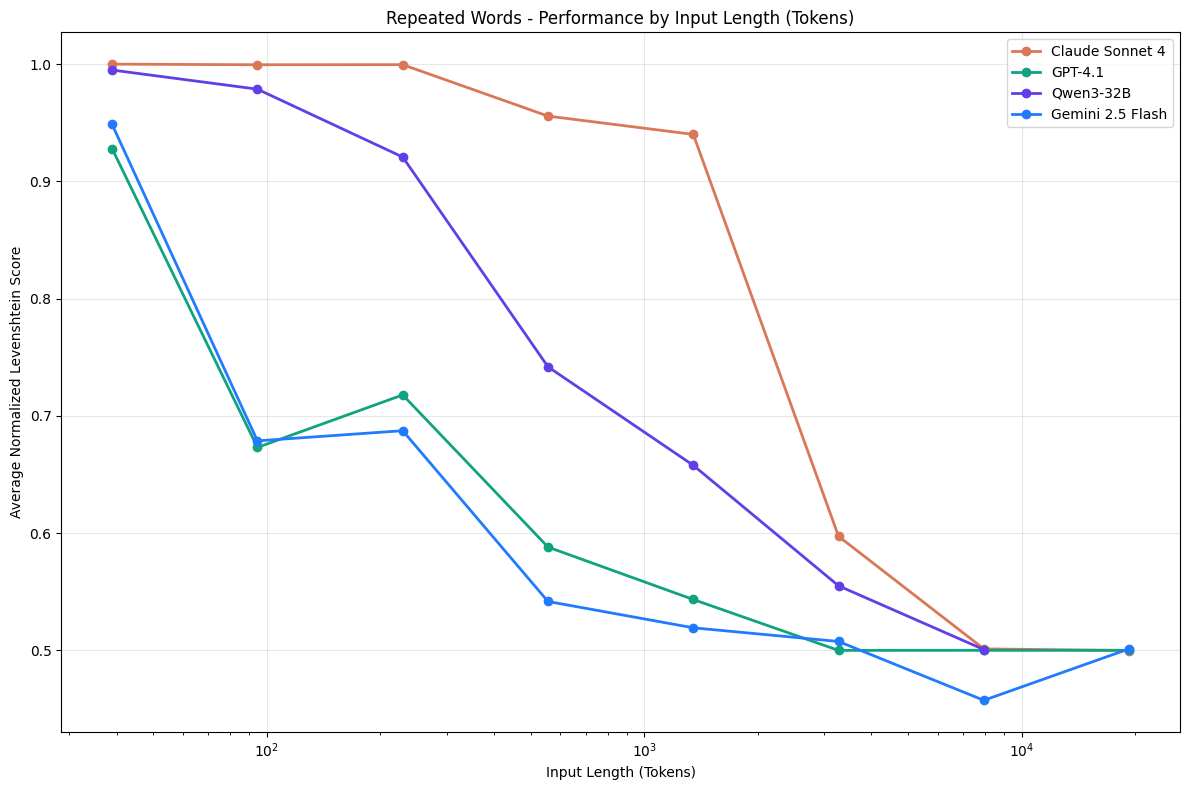
In een recent paper van het bedrijf Chroma laten ze zien dat de context windows van de meest vooruitstrevende taalmodellen in geval van specifieke tests (zoals Needle in a Haystack en Repeated Words) lijden onder iets wat ze Context Rot noemen, ook wel bekend als Context Degradation Syndrome. Dit betekent in essentie dat een taalmodel meer vergeet, minder kan en minder ziet, naarmate meer van het context window van een taalmodel gebruikt wordt.
Het context window is het geheugen van het taalmodel, waarin je je eigen bronnen en conversatiegeschiedenis kunt toevoegen zodat je taalmodel daaruit kan putten. Je zou het met een beetje fantasie kunnen zien als het RAM-geheugen van een computer.
Nu moet je altijd voorzichtig zijn als de visboer waarschuwt tegen de schadelijke gevolgen van vlees en groenten. Chroma heeft beslist baat bij enig wantrouwen in het context window van taalmodellen, omdat het producten biedt die direct concurreren met wat het context window in potentie kan.
Maar Chroma is niet de enige, eerder hebben andere papers (I, II) al een degradatie aangetoond in de (deel-)resultaten van een taalmodel naarmate meer van het context window wordt gebruikt. Context Rot, of CDS, is dus echt een ding.
In de praktijk
Maar waarom is Context Rot belangrijk en waarom moet je dat niet willen? Ook dat hangt sterk van de gebruikscontext af. In een langlopende conversatie raakt het taalmodel op een bepaald moment de draad kwijt. In intelligente applicaties kan het de trefzekerheid van agents negatief beïnvloeden, bijvoorbeeld dat het vaker de verkeerde keuzes – in stochastische processen spreek je minder vaak over of het lukt of niet lukt, maar meer wat de slagingskans is.
Stel, je gebruikt Gemini 2.5 Flash of Pro, waarbij je weet dat je een context window hebt van 1 MB. Dit is in de wereld van taalmodellen een context waar je echt wat mee kan. Stel nu dat je een agent hebt gebouwd die op basis van een document (bijvoorbeeld OpenAPI documentatie van een endpoint) een selectie moet maken. Je zou dan kunnen kiezen om het gehele document in het context window te laden. Bijvoorbeeld de Jira OpenAPI documentatie voor de Cloud is 3,5 MB. Als je dat in AI Studio inleest, dan kun je zien dat dat ~900k tokens van het context window consumeert (zie screenshot), oftewel ongeveer 90% van wat beschikbaar is.
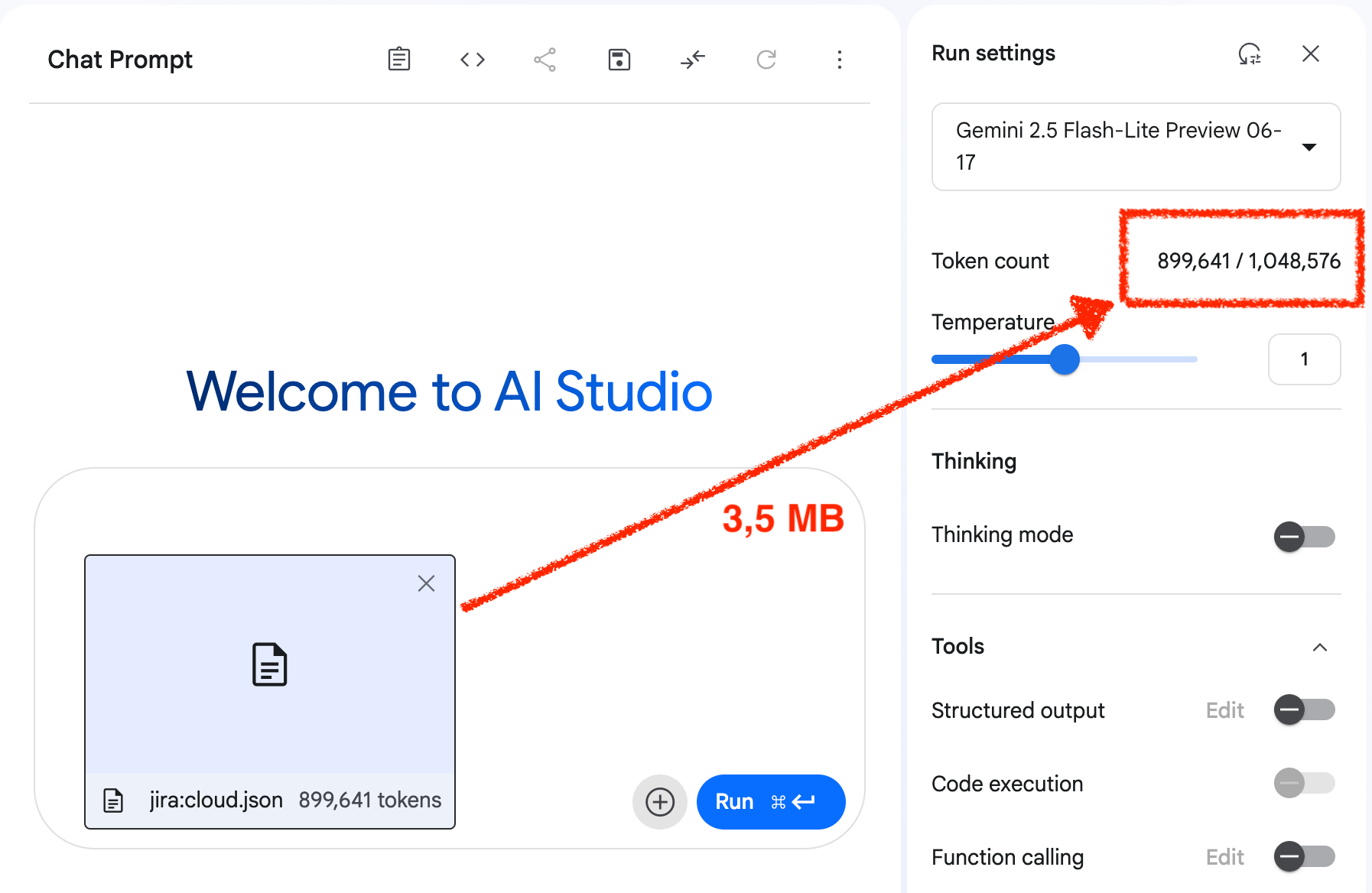
Naast dat dit kostbaar kan zijn – prijzen worden doorgaans afgerekend per 1 miljoen tokens, waarvan nu voor ieder van je calls al 90% in gebruik is – is de call naar de agent trager, maar bovenal, heeft het taalmodel te lijden onder een zekere mate van Context Rot. Dat kan zich manifesteren, maar dat kan ook verborgen blijven. Ook daar is het een kansspel.
Om de kosten concreter te maken: stel dat je je agent laat werken met het Sonnet 4 taalmodel, dan zou je al $2,70 mogen aftikken voor één call. En dat terwijl een vele malen goedkoper model zoals Gemini 2.5 Flash-Lite in dit geval hetzelfde kan doen, maar dan voor slechts $0,09.
Oplossing: gezonde context
Eén van de auteurs van de paper, Kelly Hong, geeft aan dat een focused prompt meer waarde heeft dan een full prompt. Zaak is dus als eerste na te denken over wat een agent nodig heeft. In het voorbeeld boven moet het taalmodel een endpoint kunnen selecteren. Het volstaat dan om HTTP methode, path, description en summary te gebruiken. Meer heeft het taalmodel niet nodig.
In Java kun je de OpenAPI documentatie uitlezen met de Swagger parser library. Daar voer je instructies in om de bovengenoemde informatie op te halen en te vertalen naar een gestructureerd JSON formaat – taalmodellen houden van structuur! – en dat document voed je vervolgens aan AI Studio om de verschillen te bestuderen. Voila, ~86% reductie in gebruik van het context window.
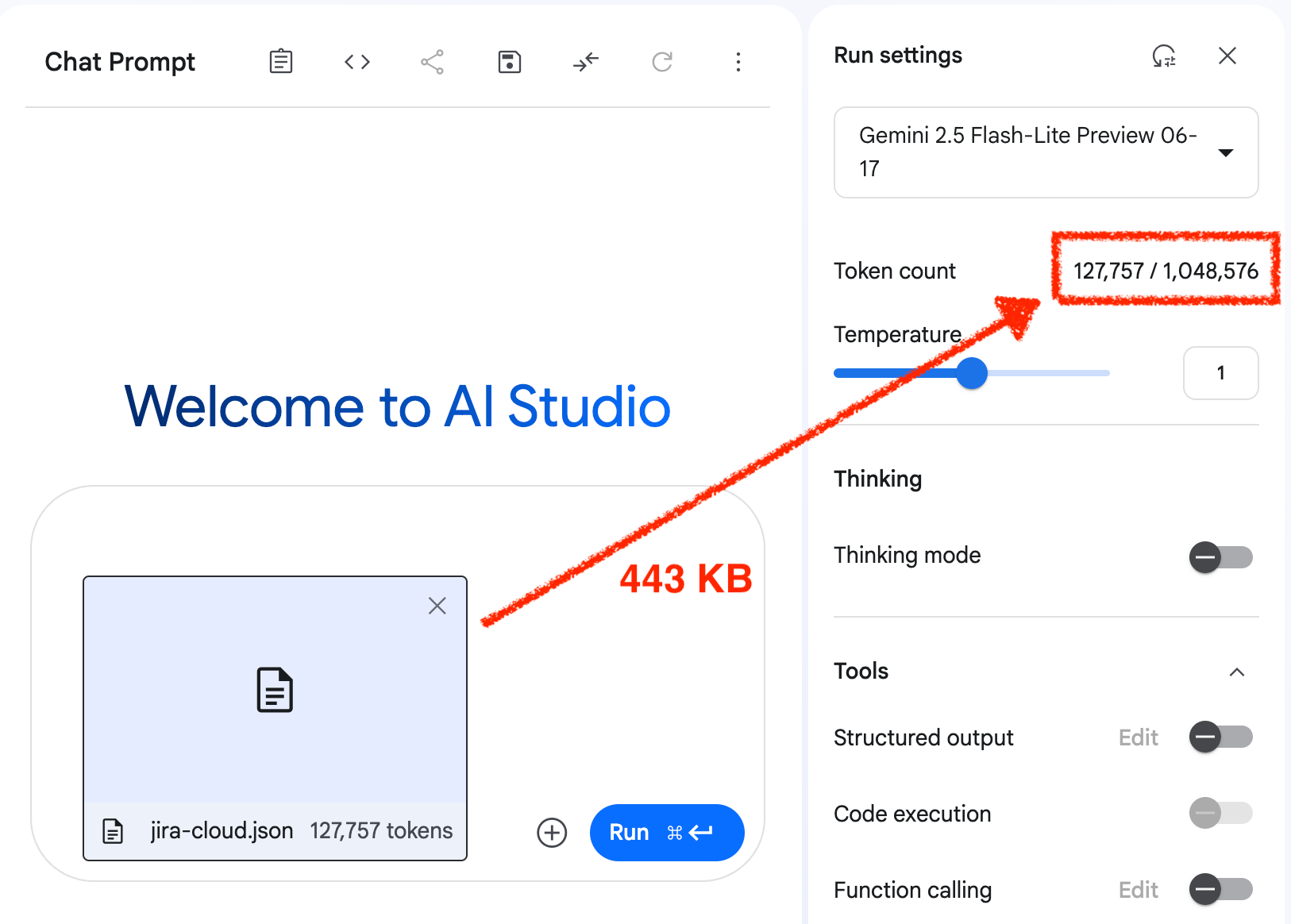
Je taalmodel heeft precies de context die het nodig heeft (focused prompt) en niet meer dan dat. Eén run van de agent is nu 7x goedkoper, sneller in de uitvoering en geeft minder kans op Context Rot. De kosten liggen in het beter voorbereiden van de prompt, oftewel de activiteiten vallende onder Context Engineering.
Om grip te houden op hoe groot een context window is, kun je een separate call maken naar de provider van het taalmodel om de gebruikte tokens te berekenen. In een multi-tenant omgeving is het sowieso nuttig om inzicht te hebben in welke gebruikers de meeste kosten maken op basis van taalmodel en tokencount. Wellicht handig voor doorbelasting? Voor een individuele context kun je een breakdown maken van de prompt onderdelen (zie onder), zodat je weet waar je je pijlen op moet richten als je wil optimaliseren.

De waarde van Context Engineering
Bij het bouwen van intelligente applicaties wordt het steeds belangrijker om goed na te denken over hoe je je prompt opbouwt. Je denkt na over wat een agent nodig heeft om tot de juiste beslissing te komen en voedt het model met enkel dat en niet meer. Je monitort en registreert het gebruik, zodat je bij kan sturen. Daarmee verklein je niet alleen de kans op Context Rot, maar wordt op alle vlakken de werking van je agent beter.



