Het pleidooi voor BeanMapper
In Java-applicaties worden conform best practices aparte klassen gebruikt voor invoer en uitvoer. BeanMapper ondersteunt dat design pattern door de overheveling van data te vereenvoudigen.


Wij hebben een library geschreven waarmee in een Java-applicatie gelijksoortige data automatisch van de ene klasse naar een andere klasse wordt gekopieerd. Deze library heet BeanMapper. Dit artikel is geschreven om de bestaansreden van BeanMapper toe te lichten.
De entiteit zelf voor invoer en uitvoer
In een Java-applicatie waar gebruik wordt gemaakt van JPA / Hibernate voor het opslaan van entiteiten, kun je in theorie de entiteit zelf gebruiken om invoer vanuit de browser en uitvoer naar de browser te regelen. Dat ziet er dan als volgt uit:
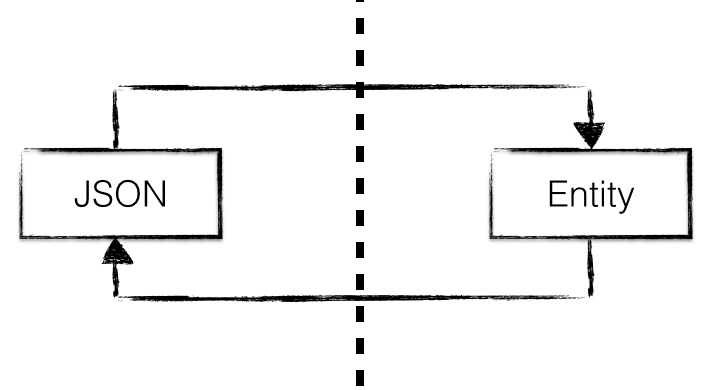
Dit patroon introduceert echter wel een aantal problemen:
- vuile invoer; het wordt voor partijen mogelijk om velden in de entiteit aan te passen, ook als deze niet aangepast zouden mogen worden. Je kunt hierbij denken aan verwijzingen naar andere records, wachtwoorden of rechten in een systeem.
- vuile uitvoer; alle velden van een entiteit worden in principe meegegeven aan de buitenwereld, ook velden die je in principe niet wil ontsluiten. Zelfs als de gebruiker de velden niet direct ziet, worden ze wel meegegeven en zijn ze vanuit een moderne browser eenvoudig in te zien, met bijvoorbeeld DevTools.
Scrubben van invoer en uitvoer?
Je kunt ervoor kiezen om met maatwerk-code de invoer in de gaten te houden en bijvoorbeeld specifieke velden uit de invoer te scrubben alvorens de data te accepteren. Eenzelfde oplossing staat tot je beschikking bij het genereren van de uitvoer.
Maar het scrubben van in- en uitvoervelden is niet zonder risico's, een aantal technisch van aard, maar zeker niet in de laatste plaats dat je je continu bewust moet zijn welke velden wel en welke niet opgeschoond moeten worden. Vergeet er één en de deur staat weer wagenwijd open.
Best practice: aparte klassen voor in- en uitvoer
Het is gebruikelijk om aparte Java klassen te maken voor in- en uitvoer. De invoer klassen worden gekoppeld aan formulier-logica en de uitvoer-klassen aan bijvoorbeeld data voor tabellen of lijsten in schermen. Deze klassen zijn doorgaans volwaardige subsets van de entiteit. Dat ziet er dan als volgt uit:
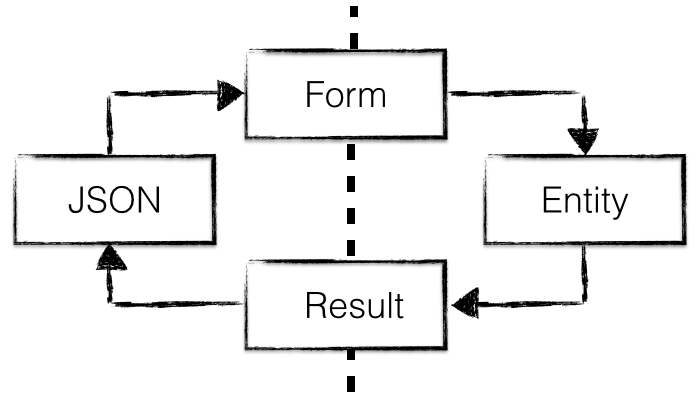
Alleen als je dat doet, ga je logica moeten introduceren die de kopieerslag uitvoert. Je schrijft dan regels die de data uit de bron haalt en plaatst in het doel, zoals dit:
// Mapping from Form to Entity
Car car = new Car();
car.setOverrideCode(form.overrideCode);
car.setLicensePlate(form.licensePlate);
// Mapping from Entity to Result
CarResult carResult = new CarResult();
carResult.id = car.getId();
carResult.licensePlate = car.getLicensePlate();
carResult.owner = car.getOwner();
Automatiseren van de overzetting
Het feit dat de in- en uitvoer objecten volledige subsets zijn van de entiteit, maakt dat het mogelijk is om te automatiseren. Je kunt een tool opdracht geven om voor alle overeenkomstige velden de inhoud van de bron naar het doel te kopiëren. Dat ziet er dan als volgt uit:
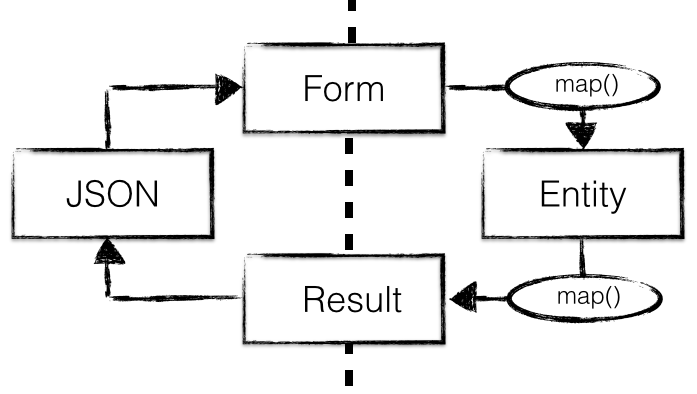
In code is het dan een betrekkelijk eenvoudige handeling geworden:
BeanMapper beanMapper = new BeanMapper();
// Mapping from Form to Entity
Car car = beanMapper.map(form, Car.class);
// Mapping from Entity to Result
CarResult carResult = beanMapper.map(car, CarResult.class);
Daarom dus BeanMapper
Velden die niet bestaan, worden niet meegenomen. In plaats van dat je én de Form/Result klassen én de logica om de data over te zetten, hoef je enkel de eerste groep te onderhouden. Het is een solide patroon met solide tooling waarmee je veilig software voor je klanten kunt bouwen.
Voor wie interesse heeft, BeanMapper is beschikbaar als open source library. Wij gebruiken zelf Open Source en geven daarom graag wat terug aan de community.



