De financiële afwegingen bij de inzet van LLM's
Taalmodellen (LLM's) brengen uiteenlopende kosten met zich mee. De dure en slimme zijn tot wel honderden keren duurder dan kleine en snelle taalmodellen. Het is zaak om goed na te denken welk taalmodel minimaal nodig is voor de eigen business case en daarvoor te gaan.


Er staan zoveel taalmodellen tot onze beschikking, hoe weet je nu waar je voor moet kiezen? Bij 42 maken we vooral gebruik van Anthropic's Claude en Google's Gemini. Claude wordt vooral ingezet als coding assistent, terwijl Gemini onder meer in applicaties wordt ingebouwd, ter ondersteuning van bedrijfsprocessen.
De kosten voor deze modellen lopen echter sterk uiteen, net als de kwaliteiten ervan. Laten we de modellen van Anthropic en Gemini eens onder de loep nemen en kijken wat de verschillen zoal zijn en dan nogmaals het vraagstuk onder de loep nemen – hoe kiezen we voor onszelf het juiste taalmodel?
De Anthropic flagship modellen
Anthropic heeft prachtige tooling voor ontwikkelaars. De Command-Line Interface (CLI) ontwikkelomgeving Claude Code is vernuftige technologie die het ontwikkelproces uitstekend ondersteunt. In combinatie met goed functionerende taalmodellen zoals Opus 4 en Sonnet 4, houdt Anthropic zich op in een warm plekje in het hart van menig ontwikkelaar.
Anthropic is wel duur. En het context window van slechts 200k is beduidend kleiner dan dat van Google met maar liefst 1 MB, wat soms tot creatieve oplossingen leidt om toch maar de AI te voeden met de juiste context.
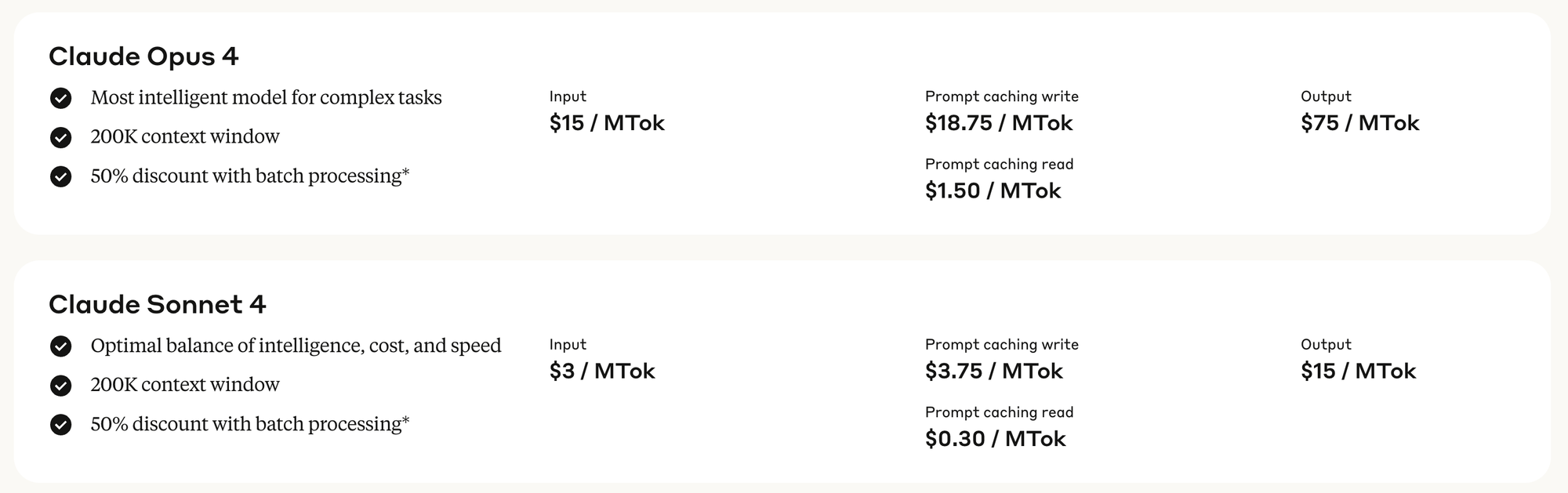
Claude Opus 4
Opus 4 is het duurste model wat Anthropic te bieden heeft. Anthropic stelt zelf dat Opus een goede planner is en Sonnet de beste uitvoerder en adviseert ontwikkelaars de LLM's in die rollen te plaatsen.
Tips:
— ClaudeCode (@claude_code) June 23, 2025
1) Plan with Opus and execute with Sonnet. Shift + Tab to toggle.
2) Use https://t.co/bTiqIJvSMx to clarify project terminology and venv setups.
3) Use `ccusage` to track usage. Claude Max subscription offers 5x ($100/month) and 20x usage ($200/month). https://t.co/NYdLD2V4h0
Claude Sonnet 4
Sonnet heeft een bewogen jaar achter de rug. Claude Haiku 3.5 heeft en had een goede reputatie, maar Claude Sonnet 3.7 bouwde daar niet op voort. Menig developer werd overvallen door de geestdrift waarmee 3.7 codebases te lijf ging, om niet te zeggen dat de doodsangst soms om het hart sloeg, terwijl naarstig naar de panic button werd gezocht.
Met Sonnet 4 heeft Anthropic dat euvel verholpen. De LLM volgt nauwgezet instructies op. Waar je vooral op moet letten is dat je duidelijk opschrijft wat je wil en een gedegen plan maakt. Kan sowieso geen kwaad om daar goed over na te denken.
De Google Gemini familie
Google heeft eigenlijk pas sinds zeer recent (einde Q1 van 2025) een inhaalslag gemaakt met hun taalmodellen. De 2.0 serie was niet om over naar huis te schrijven. In korte tijd kwamen zij met de krachtige 2.5 lijn, die het goed deed in benchmarks. De tooling werd in korte tijd geïntegreerd in hun omvangrijke suite.
Gemini 2.5 Pro
- $2.50 / miljoen tokens input
- $15 / miljoen tokens output
2.5 Pro kan zich meten met Sonnet 4. Wat Google vooral mistte was een ontwikkelomgeving. Je kon de taalmodellen goed bevragen in Gemini en in de AI Studio, of zelf via de coding agent Jules, maar ze hadden nog geen eigen ontwikkelomgeving a la Claude Code. Tot 25 juni, de dag waarop ze Gemini CLI lanceerden, tegen fenomenaal lage prijzen, waar de hoge heren bij Anthropic vast niet blij van worden.
Say hello to the @geminicli, a local CLI to help you build and maintain software with 1,000 free Gemini 2.5 Pro requests per day : ) pic.twitter.com/tf9wMXNzyI
— Logan Kilpatrick (@OfficialLoganK) June 25, 2025
Gemini 2.5 Flash
- $0.30 / miljoen tokens input
- $2.50 / miljoen tokens output
Flash houdt het midden tussen Pro en Flash-Lite, het is sneller en goedkoper dan de eerste en slimmer dan de laatste. Voor de niet al te complexe taken, waar het goed kan worden voorzien van jouw context, is het waarschijnlijk ruim voldoende. Het kostenverschil met Pro is aanzienlijk, dus het is beslist de moeite om daar bewust mee om te gaan. Flash is het werkpaard van de Gemini-familie.
Gemini 2.5 Flash-Lite
- $0.10 / miljoen tokens input
- $0.40 / miljoen tokens output
2.5 Flash-Lite is net nieuw en enkel nog beschikbaar in preview modus. Het model is bloedsnel, kost bijna niets, maar is duidelijk minder begaafd dan zijn broertjes. Waarom dan toch Flash-Lite kiezen? Omdat je soms simpelweg niet meer nodig hebt dan Flash-Lite.
De uitdaging is om te bepalen wanneer dat zo is. Je zou bijvoorbeeld eigen evals kunnen opstellen voor jouw business case waarbij je verschillende taalmodellen meerdere malen runs laat uitvoeren en aan elk taalmodel een succespercentage hangt. Als Flash-Lite een vergelijkbare prestatie geeft als de duurdere modellen, dan is dat een uitgelezen kans om Flash-Lite in te zetten.
Ik moet overigens bekennen dat Flash-Lite mij recent op het verkeerde been had gezet. Na een test gedraaid te hebben, verwierp ik het model als niet goed genoeg. Echter, na erover nagedacht te hebben, bleek het bij nader inzien een kwestie te zijn van ontbrekende kennis. De kleine, snelle modellen kunnen immers alleen maar klein en snel zijn omdat ze minder kennis bevatten dan de wereldmodellen. Het probleem was simpel op te lossen door de juiste context mee te geven, waarna Flash-Lite de opdracht wel goed genoeg kon uitvoeren.
Overzicht
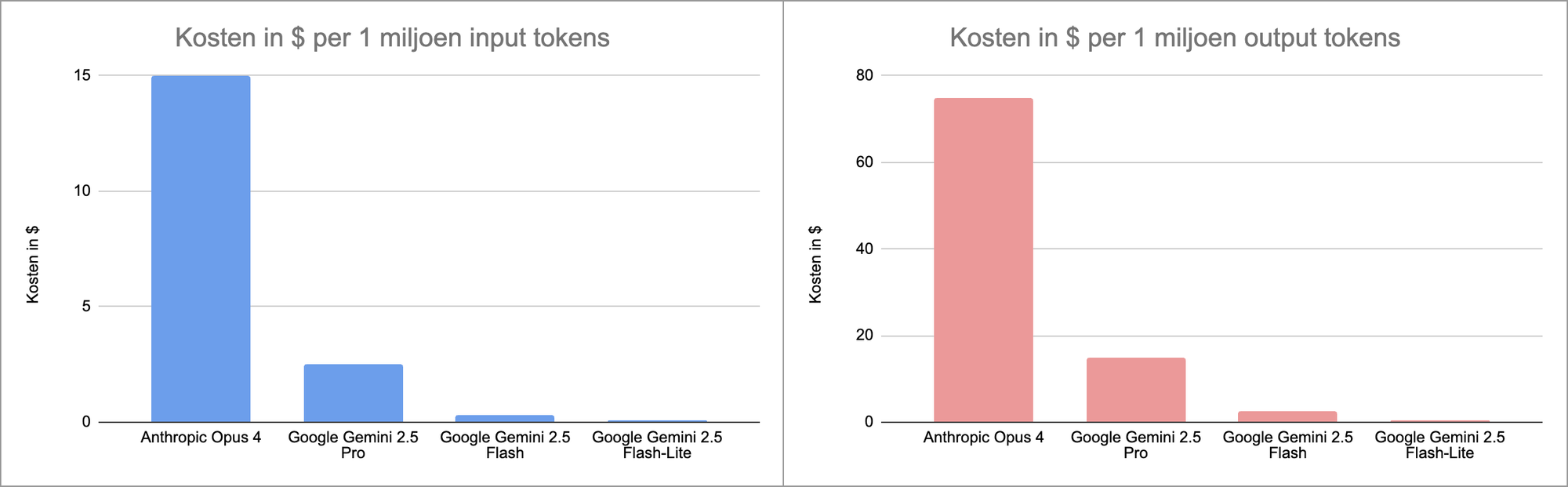
Als je de modellen op rij zet en je kijkt door de oogharen heen, dan zie je dat Opus 6x duurder is dan Pro, die zelf meer dan 8x duurder is dan Flash, die op zijn beurt weer 3x duurder is dan Flash-Lite. Opus is 150x – 180x duurder dan Flash-Lite. Dit prijsverschil rechtvaardigt een doorwrochte keuze in het bepalen welk taalmodel ingezet moet worden.
De kwestie – wanneer welk taalmodel?
Kiezen voor een taalmodel begint bij bewustzijn dat een afweging gemaakt moet worden tussen trage slimheid enerzijds en snelle, goedkope respons anderzijds. De kwestie komt dan op één eenvoudige vraag neer:
Hoe slim moet mijn taalmodel minimaal zijn?
Waarom minimaal? Omdat overkwalificeren je raakt in je portemonnee en in de snelheid waarmee de gebruiker van terugkoppeling kan worden voorzien.
Hoe bepaal je wat minimaal nodig is?
Door te evalueren. Je legt de taalmodellen representatieve opdrachten voor die ze moeten uitvoeren en meet de resultaten. Om de willekeur eruit te filteren doe je dat per taalmodel meerdere malen. Als de taalmodellen vergelijkbaar scoren, dan weet je dat je kunt kiezen voor het snellere en goedkopere model. Scoort het slimmere model beter, dan moet je mogelijk daarvoor kiezen. Maar misschien wil je dat juist niet, omdat bijvoorbeeld je taalmodel zo vaak wordt aangeroepen, dat het je maandelijkse kosten teveel aanjaagt. Je bepaalt uiteraard zelf hoe hoog je de kwaliteitslat legt.
Ergens op de lat van 1x tot 180x de kosten voor een taalmodel ligt de sweet spot voor jouw business case. Essentie is om bewust te zijn van de afwegingen en weloverwogen keuzes daarin te maken.



